ChinaFile is a project of the Asia Society. This website is licensed under CC BY 4.0.
Blocking Circumvention Technologies
Jessica Batke
Senior Editor for Investigations at ChinaFile
Laura Edelson
Assistant Professor of Computer Science at Northeastern University
China’s censorship system not only targets “dangerous” content, but also targets users’ attempts to evade the system itself. After all, Beijing spends a lot of money and effort to curate the domestic information environment and keep “dangerous” information outside the country’s digital borders. There would be no point to such an undertaking if it were trivially easy to sidestep the censors.
Since about 2010, China has put a special premium on hunting down and blocking information about and access to censorship circumvention tools. The censors are engaged in a seemingly endless arms race with circumvention tool developers, who try to create countermeasures after each new block. (It is worth mentioning that Chinese authorities do not block every single possible circumvention tool. Bowing to economic necessity, the government maintains a list of approved technologies that allow foreign businesses and others to circumvent the censorship system in order to send secure emails or visit blocked websites. These approved circumvention tools also likely allow the government to surveil communications sent within them.)
For average citizens hoping to evade censorship, the barriers to entry have gotten higher as circumvention information becomes harder to find and many solutions require at least some technical know-how. Through its DNS
, IP
, and HTTP
filtering systems, China long ago pre-empted basic circumvention methods that websites might themselves employ, like changing IP addresses
or domain names. And easy-to-use encrypted apps like Signal aren’t available in-country thanks to restrictions placed on app stores.
Many of the remaining circumvention mechanisms rely on a simple premise: showing a false destination to the censor. The censor sees the false destination, thinks it’s ok, and lets the traffic through to the false destination. The false destination (like “aws.amazon.com”) then forwards on the internet traffic to the real destination.
The Rise and Fall of Domain Fronting
For a few years in the 2010s, a practice called domain fronting offered a censorship workaround to websites and apps (like Telegram and Signal) otherwise banned in China. Domain fronting tweaks the standard settings when sending an HTTPS message, making sure that a censor only sees a false destination (a front) and hides the real destination deeper inside the HTTPS encryption.
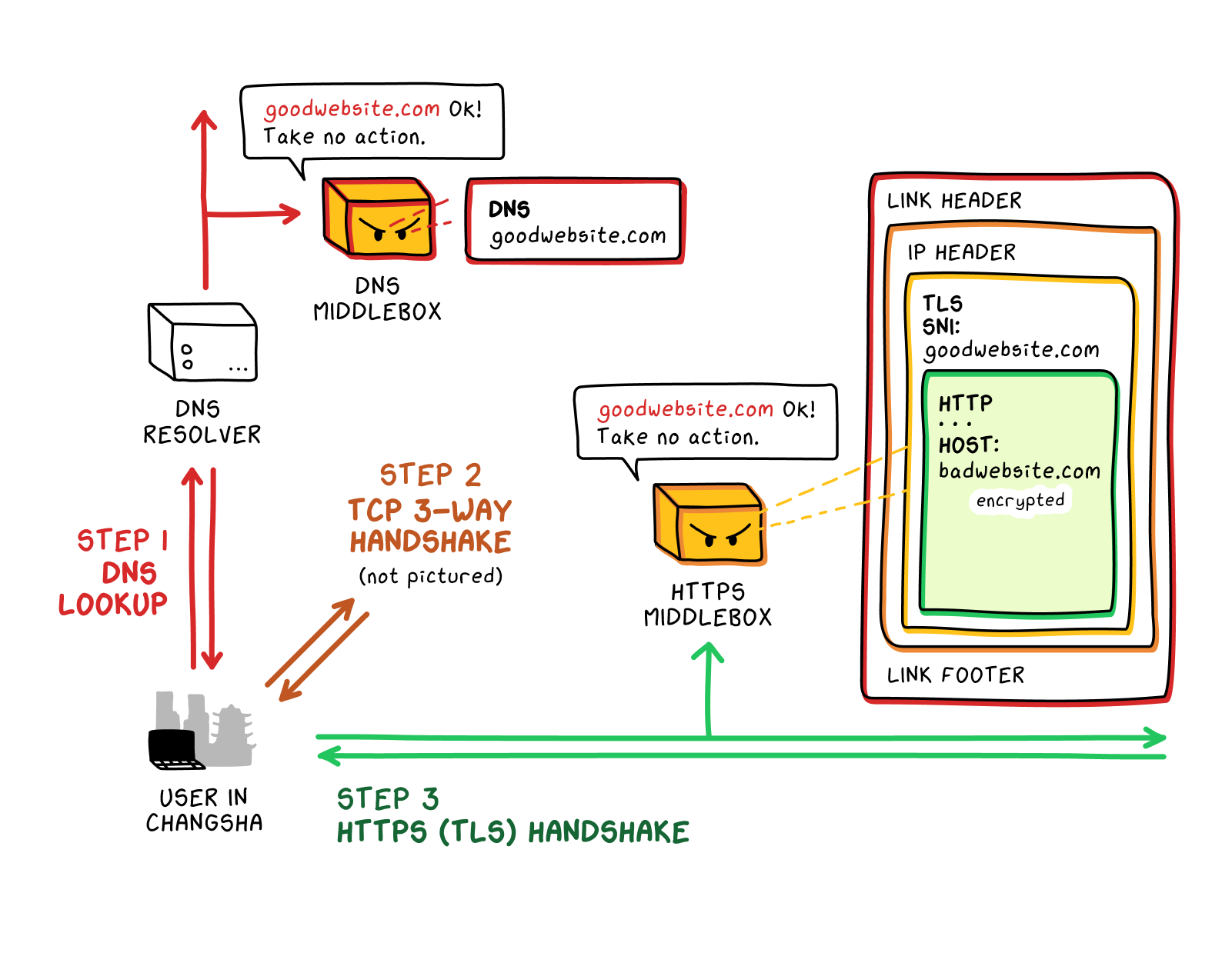
A standard HTTPS
connection requires several initial steps: first, a DNS lookup to turn the user-typed domain name into an IP address; second, a TCP handshake to make the initial connection between user and server; and third, a TLS handshake, which includes sending the server Name Identification (SNI)
. Once the TLS handshake is complete, the user can send a regular HTTP
message, safely encrypted within the overall HTTPS (TLS) protocol.
Domain fronting exploits the fact that a destination domain name appears in three different places when establishing an HTTPS connection: in the initial DNS lookup
, in the SNI field, and in the HTTP host header. The former two are unencrypted, or cleartext. The HTTP host header, snug within the HTTPS (TLS) encryption, is not readable without decryption. So it is possible to list an uncensored front website in the DNS lookup and in the SNI field, with a censored target website in the HTTP host header, and not trigger any DNS or HTTPs filtering:
There are two keys to this technique working. First, the front websites have to actually forward the HTTP
request to the target destination—many websites will simply not forward traffic that isn’t actually directed to them. This is a reasonably easy barrier to overcome; even an individual with minimal technical knowledge could set up a server
outside China that would forward such traffic. Were someone to do this, however, it would also be reasonably easy for authorities to block that server’s IP address
and thereby stop the domain forwarding.
This is where the second key comes in: The front websites should be large and economically important enough that censors (in China, Russia, or anywhere else) would be hesitant to block them. Such websites might include major multinational sites like Amazon/AWS. The censors then have to choose between blocking the front website entirely—”blocking all”—or knowingly letting the unwanted traffic evade the system—”blocking none.” As a computer scientist toldTheWall Street Journal in 2015, “The philosophy [behind domain fronting
] is to make it as expensive to block as possible, so that there would be a lot of collateral damage.”
For a number of years, companies that host large quantities of web traffic, such as Amazon/AWS, Google, and Microsoft/Azure, had servers that would forward such traffic as a default. For example, someone in China using a domain fronting
tool might send their packets
to an AWS server. The AWS server would accept these packets, and upon unpacking them, realize they were actually meant for the encrypted messaging app Signal. The AWS server, ignoring the mismatch, would simply forward the traffic to Signal. These companies thus became important, if largely passive, players in the censorship circumvention ecosystem. Technologies that relied on domain fronting, like Telegram and Signal, benefited from the resulting collateral freedom.
The vulnerability in this technique, however, lies with the companies themselves. The companies don’t have to forward traffic not actually directed to them—they can choose to stop serving as fronts. Over the lastdecade, that is exactly what happened. Some observers credit Russia (another major nation-state censor) with applying enough pressure to Google and Amazon specifically that they reconfigured their systems to disallow domain fronting
in 2018. Now, domain fronting at scale is no longer the censorship solution it had been just a few years ago.
Traffic Routing through Proxies
Many of the most popular mechanisms to evade censorship in China rely on proxy servers. Proxy servers, or proxies, are simply machines that serve as middlemen—they accept and forward on traffic that is ultimately meant for another server. They are the front that China’s censorship system sees instead of the real destination. Different organizations may set up their proxy networks in different ways, but they all fundamentally involve a user, a destination server, and at least one proxy server in between the two, relaying traffic between the user and the destination.
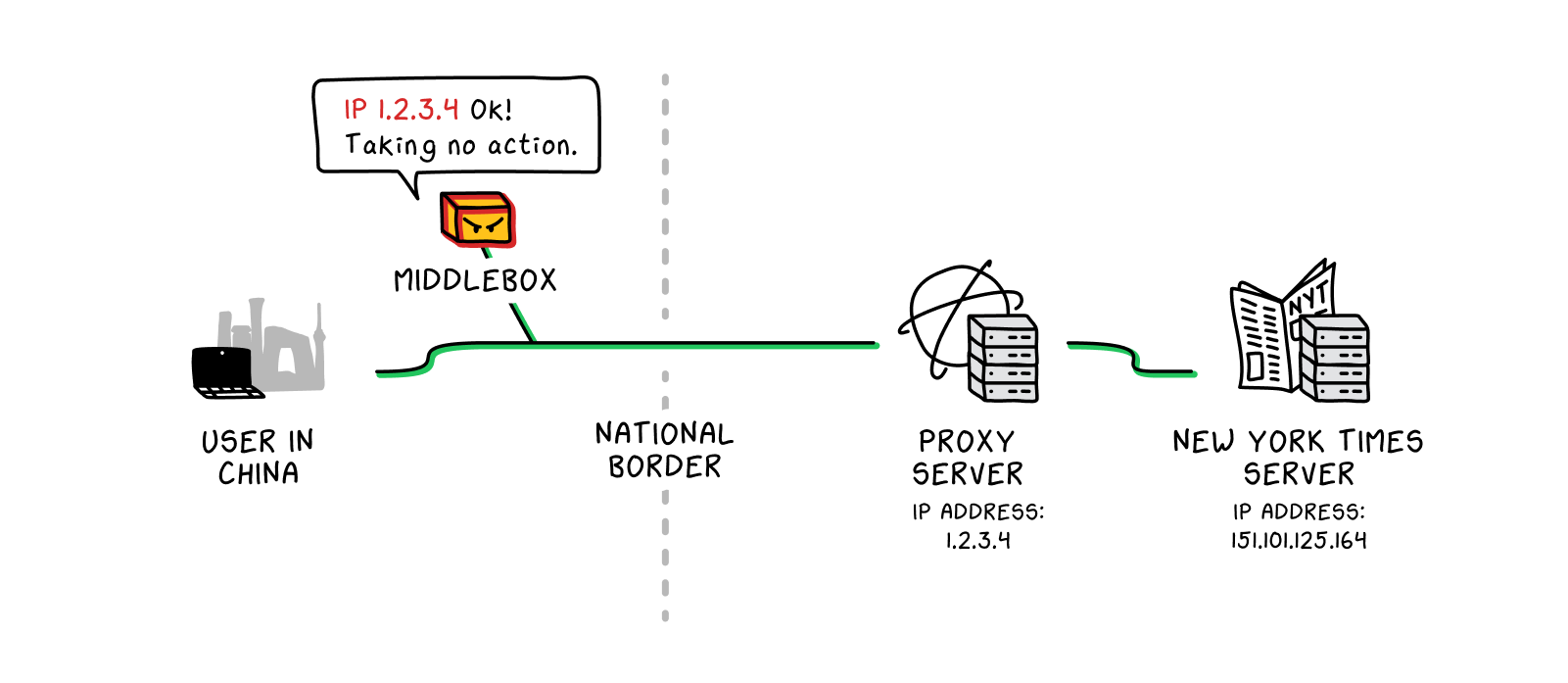
It works like this: Someone in China hoping to read TheNew York Times (whose website is banned in China) may try to use a proxy server to connect. Using the proxy software of their choice, they would type in “www.nytimes.com.” Instead of doing a DNS lookup
right there from the computer in China, the proxy software would send this request to a proxy server in another location—so all the packets
sent from the user to the proxy server would have the proxy server’s IP address
on them. A Chinese government middlebox
inspecting the packets would only see an innocuous IP address totally unrelated to TheNew York Times. Once the packets reached the proxy server, the proxy server would initiate the DNS lookup
and fetch TheNew York Times homepage. Finally, the proxy server would send TheNew York Times homepage information back to the user—again, with all the packets appearing to come from the proxy server, not from TheNew York Times.
This system works as long as the Chinese authorities do not realize that the proxy server is, in fact, the proxy server. Once they recognize the proxy server for what it is, they can easily add the proxy server’s IP address to a blocklist.
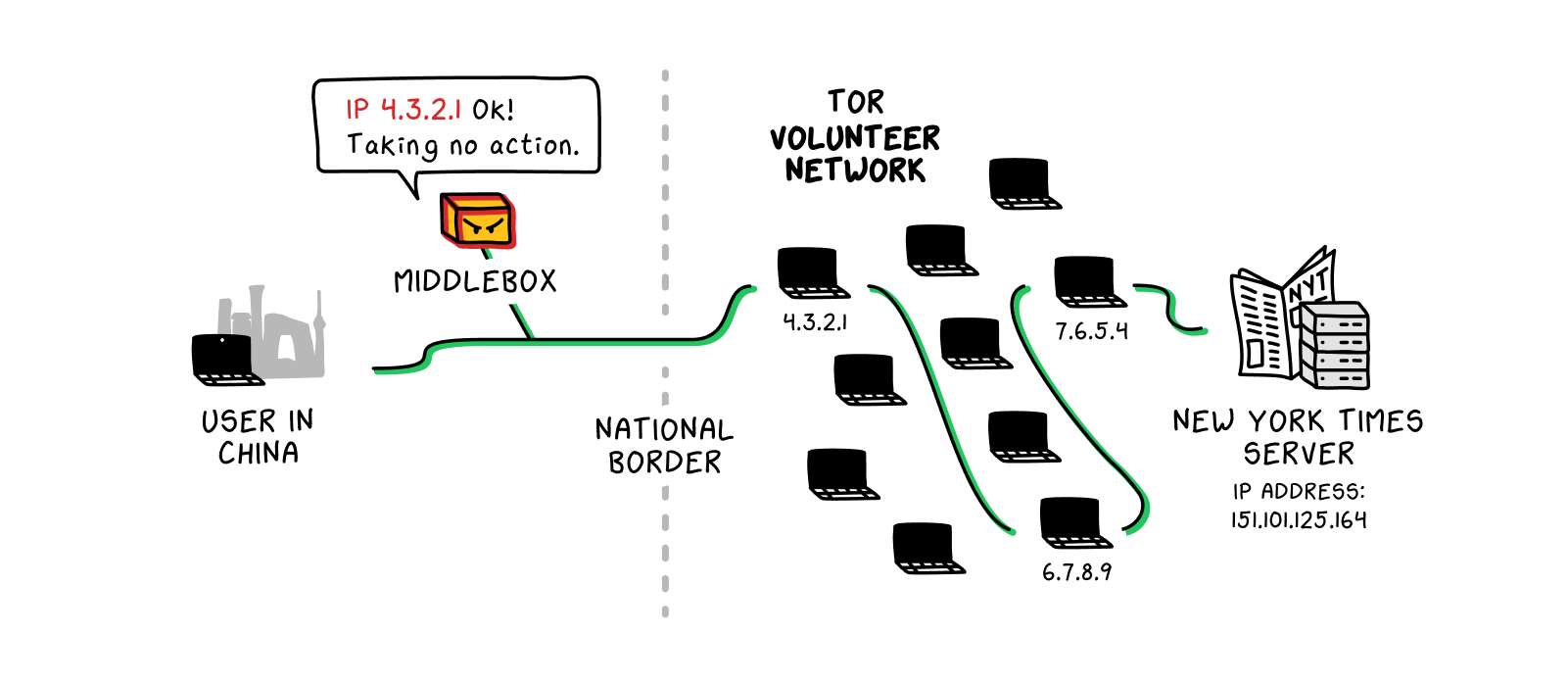
There are several different models a proxy provider might use to set up a proxy network and provide service to customers. Many companies offer virtual private network (VPN) services, which function almost exactly as described above. (Indeed, many people use the terms “VPN” and “proxy” interchangeably to refer to technologies that help evade censorship, a convention which we follow in this article.) These companies maintain the various proxy servers specifically set up to handle users’ traffic and usually route a user’s traffic through a single proxy per session. The Onion Router, software more commonly known as Tor, works in a similar way, though as a free service it depends on volunteers to run its proxy servers. It also shepherds traffic through at least three different proxy servers each time traffic moves from one endpoint to another, making it extremely difficult for a censor to discover the ultimate destination of the traffic—or, for that matter, for any of the proxy servers in the network to have information about both endpoints in the connection. Shadowsocks, a piece of software created by a Chinese programmer who later dropped out of the project under pressure from the police, uses a slightly different technical mechanism to connect to proxies, and it allows users to choose those proxies either by paying a VPN company for access or by remotely setting up their own servers outside China. Whatever the exact mechanism, a proxy provider is basically just helping a user access one or more servers that can help disguise the ultimate destination of the user’s traffic.
The Traffic Routing Arms Race
Though traffic routing does often successfully obscure a user’s browsing habits, it suffers from several key vulnerabilities. For one, it often relies on users’ discovery of information—information about how to install software, or the most recent list of functioning proxy servers
. Censors can target and block just this sort of information. For another, a motivated censor can block the IP addresses
of proxy servers just as well as it can block the IP addresses of “dangerous” websites themselves (more on that below). Circumvention tool developers and Beijing have been engaged in a silent battle on both of these fronts.
For over a decade, the Chinese censorship system has actively tried to discover proxy servers and prevent China-based users from connecting to them. (These efforts complement other non-technical means to prevent internet users in China from accessing proxies, such as forcing Apple on multiple occasions over the past decade to remove circumvention tools from its app store in China.) The following sections catalog Beijing’s shifting tactics over time, as circumvention providers worked to overcome previous blocks.
Blocking Proxies Based on Public Information
In 2009, just as the People’s Republic of China was preparing to celebrate the 60th anniversary of its founding, the censorship system took aim at Tor’s network of proxy servers
. At the time, this was a fairly straightforward task: Tor maintained a publicly-available list of proxy servers, and censors simply blocked the listed proxies’ IP addresses
. Tor then began distributing new proxy addresses via email. The following year, China’s censors learned the IP addresses of those proxies and blocked them as well. This left Tor dependent on individuals’ sharing proxy addresses directly with others in their social networks—a serious degradation in users’ discovery of circumvention information. By 2015, China’s censors were downloading and running Tor’s software to find and block proxies within a month of each new software release. And in 2016, the censors didn’t even wait for the software release. Once Tor posted the source code publicly, even before the software’s official release, censors began inspecting the code and blocking the proxies listed there before anyone in China had a chance to use them.
Blocking Proxies Based on Fingerprinting and Active Probing
Not all proxy IP addresses
are openly available online, however. China’s censorship system therefore actively works to discover additional unknown proxy servers
in order to prevent internet users within the country from accessing them. Since at least 2011, Chinese censors have employed a two-step process to detect and confirm the identity of proxy servers in order to disrupt their services. This process is on the lookout for multiple different circumvention protocols, including but not limited to Tor and Shadowsocks. The two-step process works like this:
Fingerprinting traffic. When a user in China connects (or attempts to connect) to a proxy server, the back-and-forth exchange of information during or just after a TCP or TLS handshake can provide a censor with valuable information about the nature of the connection, encryption notwithstanding. A censor monitoring the type or format of the information exchanged can determine whether or not circumvention technology is being used, and, if so, proceed to step 2.
For example, Shadowsocks software “attempts to avoid detection . . . by using encryption to appear as a uniformly random byte stream.” Essentially, Shadowsocks tries to hide in plain sight by appearing to the censor as a truly random string of characters. However, even this “randomness” can serve as a tip-off to a censor—it’s simply too random to be a normal, unencrypted packet
. In addition, when Shadowsocks creates TCP
packets, the packets tend to have a certain length, give or take some characters. Since May 2019, China’s censorship system has used these two facts to detect and block Shadowsocks traffic. After the initial TCP handshake
, the censor inspects the first data packet the user sends to the proxy server; if that packet has a high level of “entropy” (randomness) and is of a certain length, the censor determines that the traffic was likely generated by Shadowsocks, and proceeds to step 2. (The principle of fingerprinting also works against very common protocols, likeTLS.)
Active probing of suspected proxy servers. Through step 1, China’s censorship system identifies potential proxy servers, learning both the proxy’s IP address
and the type of circumvention tool it supports. With this information, the system is able to send probes to the proxy server. A probe is simply an attempt to connect to the suspected proxy server. The probe pretends to be legitimate traffic from a circumvention user—sometimes it even mimics the exact data packet that caused the system to send the probe in the first place, which is known as a replay attack. The censorship system usually sends multiple probes to the proxy server. The pace at which the probes are sent can vary over time and by circumvention tool (some being sent days or even weeks after the system flagged the proxy server in step 1). But Beijing appears to have invested in this technology over the last decade or so, as sometime in the mid-2010s the probing system began to send out some probes less than a second after completing step 1—a speed it had previously been incapable of managing.
Once the system confirms that the server is indeed a proxy server, it may block that server by IP address
—though depending on the circumvention tool, it may not impose a block every time. (Researchers working on Shadowsocks blocking in 2020 reported that only 3 of their 63 test proxy servers got blocked, even though many of them had received a flurry of probes. They couldn’t be sure why more proxies weren’t blocked, but speculated that either the decision to block is made by a human rather than automated, or that some versions of Shadowsocks they were testing were more resistant to active probing.) Once imposed, a block is usually temporary, lasting from 12 hours to several weeks, likely because many proxy providers frequently swap out proxies and IP addresses and retaining a block long-term could cause too much collateral economic and reputational damage.
China’s probes come from a wide range of IP addresses that change frequently. This means that circumvention providers can’t simply keep a list of the probes’ IP addresses and configure their proxy servers to ignore them—there are simply too many IP addresses to keep track of, and there is a decent chance that a legitimate user might eventually be assigned one of them.
In November 2021, censors implemented a second proxy-blocking mechanism that works in parallel with the two-step method described above, aimed at a variety of circumvention protocols and likely designed to catch any traffic that the two-step method might miss. This mechanism wasn’t entirely new—it was more like the repurposing of an older technique, aimed at a new target (proxy traffic). Because China has such a depth of expertise on internet censorship, it often doesn’t need to create new mechanisms out of whole cloth; it can simply dig around in its existing toolbox and modify an existing tool to get the job done. (Notably, censors had stopped using this blocking mechanism by March 2023, for reasons unknown. Still, as it represented a significant development in China’s anti-circumvention efforts, and because it demonstrates that the censors continue to rely on relatively low-tech methods to block traffic, it is worth describing here.)
The “new” mechanism employed only the first of the previous two steps: fingerprinting
(detecting encrypted internet traffic by comparing the visible parts of the packet
against a set of known patterns associated with circumvention tools). It then blocked traffic without any active probing follow-up. Researchers describing this new system hypothesized that it was, at least in part, a reaction to circumvention providers’ efforts to make their proxy servers more resistant to active probing—another escalation in the ongoing arms race.
Just like the fingerprinting
described above, the new mechanism aimed to detect and block encrypted traffic that seemed bound for proxy servers, using what researchers described as “crude but efficient heuristics” to identify such traffic. Notably, the mechanism seemed to monitor only a limited number of connections and block only a portion of encrypted traffic. Researchers speculated the mechanism limited itself in this way “to mitigate false positives and reduce operation costs.” Observing the mechanism’s behavior and working backwards to infer general rules guiding its actions, researchers posited that:
The mechanism monitored connections only to IP addresses
associated with popular data centers (i.e., those most likely to host proxy servers).
Within these select connections, it inspected only the first data packet sent after a TCP handshake
(the mechanism inspects only TCP
, not UDP, packets).
It determined whether the packet:
Had too high an entropy (appeared “too random,” meaning it was likely encrypted traffic designed to appear random).
Contained too few human-readable characters, or not enough human-readable characters, in particular locations within the packet.
Did not match popular internet protocols like HTTP
and TLS
.
If any of the conditions from #3 were met, the mechanism blocked roughly one out of every four instances. Blocking consisted of:
Dropping packets sent from the user to the proxy server. Dropping packets, rather than initiating a TCP reset
, indicated the mechanism used relatively expensive, resource-intensive in-path middleboxes.
Enforcing residual censorship
for two-three minutes.
Nearly a year after this method was implemented, in October 2022, researchers noted that another fingerprinting